Team members commonly collaborate on visual documents remotely and asynchronously. Particularly, students are frequently restricted to this setting as they often do not share work schedules or physical workspaces. As communication in this setting has delays and limits the main modality to text, members exert more effort to reference document objects and understand others’ intentions. We propose Winder, a Figma plugin that addresses these challenges through linked tapes—multimodal comments of clicks and voice. Bidirectional links between the clicked-on objects and voice recordings facilitate understanding tapes: selecting objects retrieves relevant recordings, and playing recordings highlights related objects. By periodically prompting users to produce tapes, Winder preemptively obtains information to satisfy potential communication needs. Through a five-day study with eight teams of three, we evaluated the system’s impact on teams asynchronously designing graphical user interfaces. Our findings revealed that producing linked tapes could be as lightweight as face-to-face (F2F) interactions while transmitting intentions more precisely than text. Furthermore, with preempted tapes, teammates coordinated tasks and invited members to build on each others’ work.
In Winder, users send linked tapes, which are recordings of their voice and clicks on objects on the UI design. The system generates bidirectional links between voice snippets and clicked-on objects to support navigation and understanding the receiver side.
The main components of the system’s interface are (a) the top bar, (b) the list of linked tapes, and (c) the transcript space.
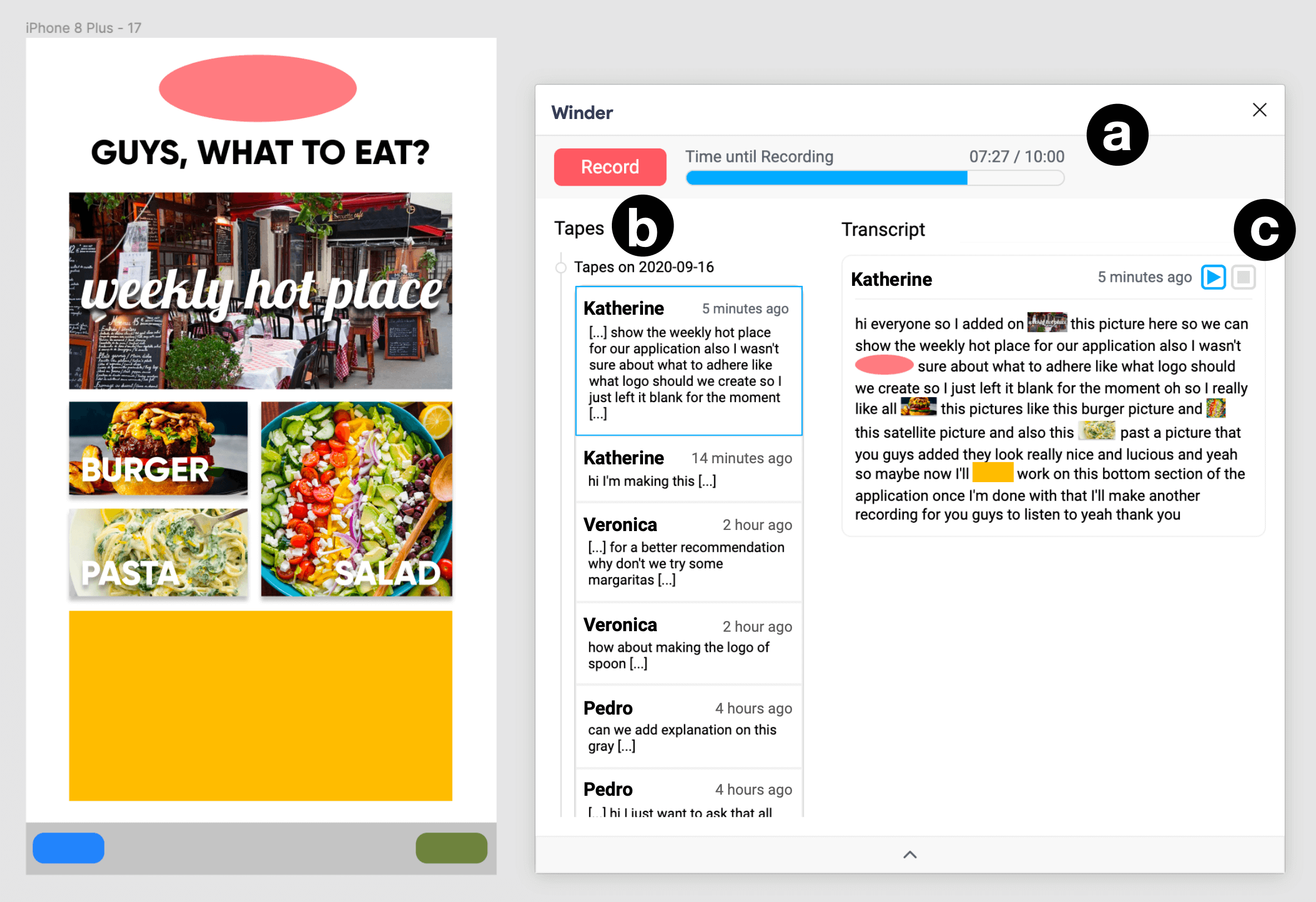
When the user plays a tape, Winder Winder displays the version of the document when the tape was recorded, and plays the voice audio while highlighting objects as they were clicked during recording.
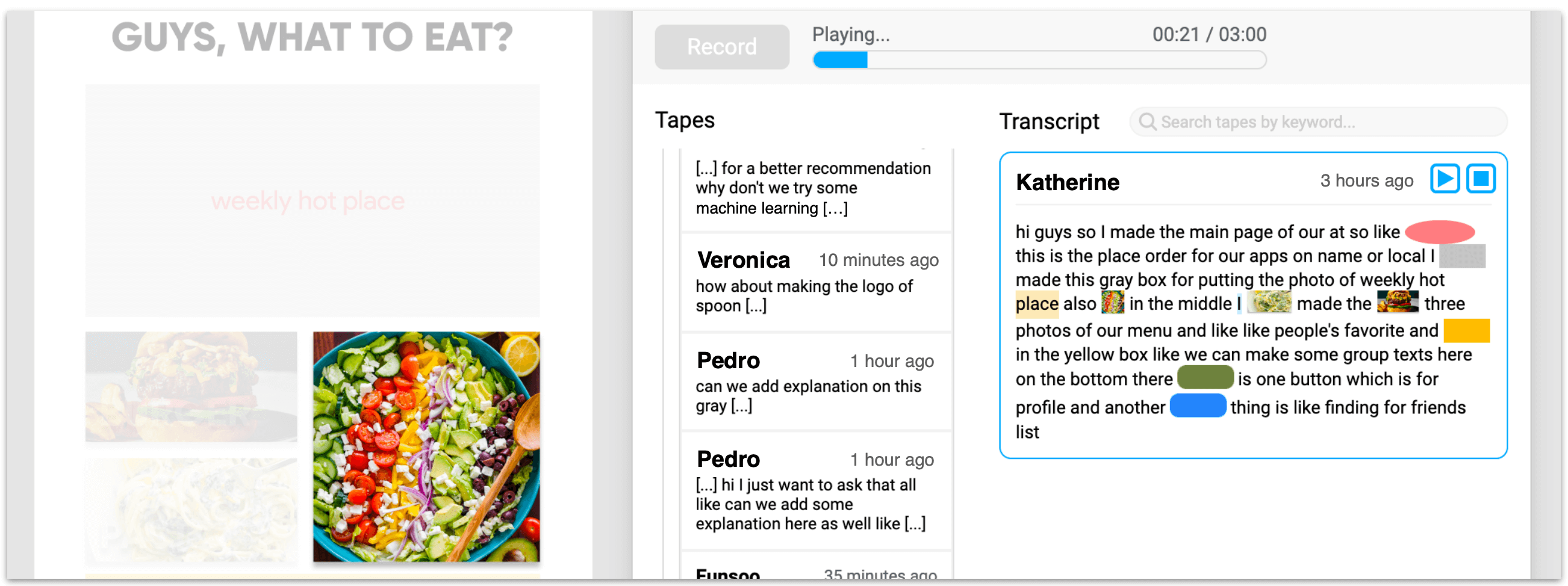
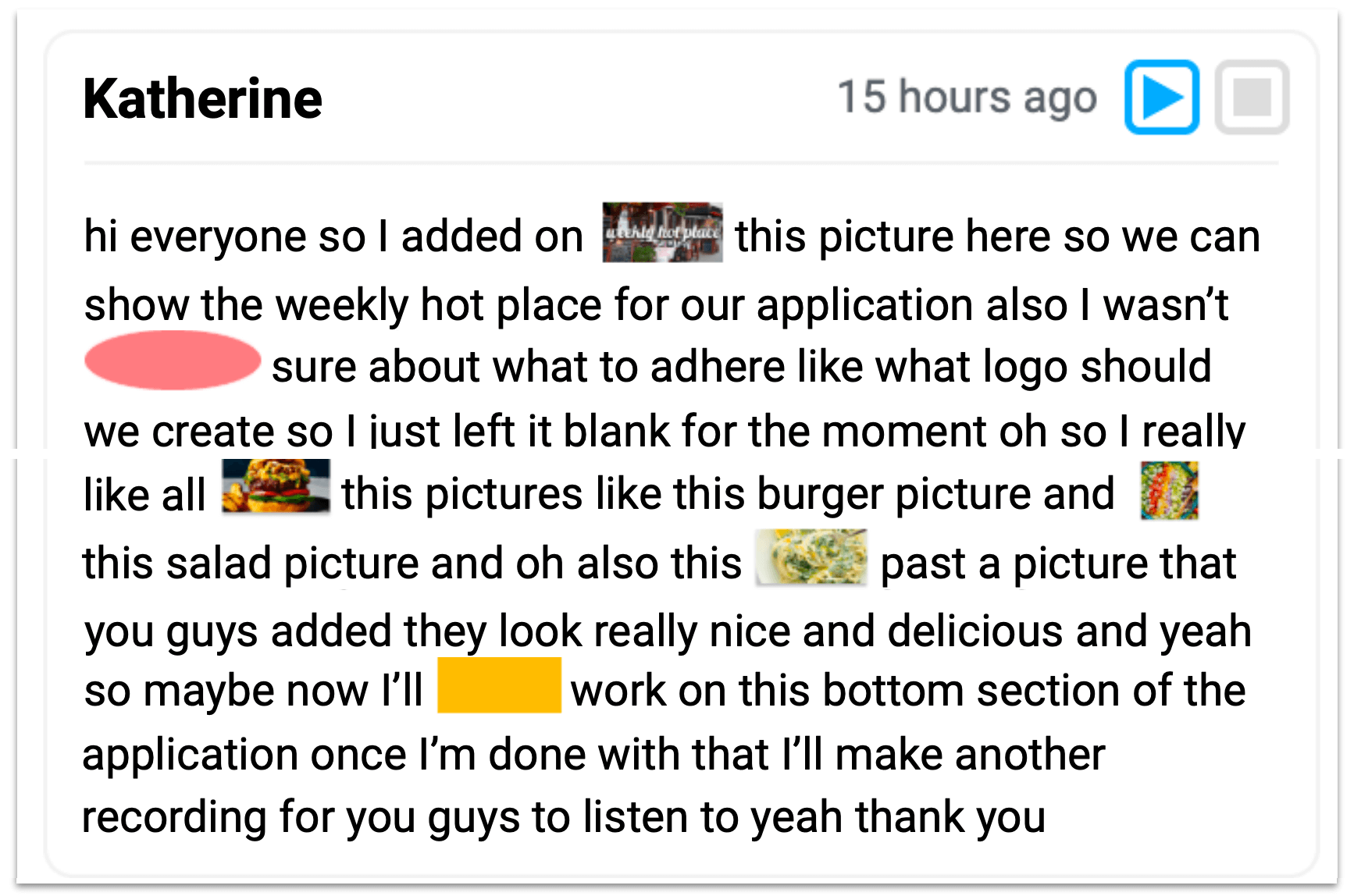
Winder provides automatic transcripts of the voice recordings (generated through speech-to-text). On the transcript, it embeds thumbnail images of the objects clicked during the recording inline with the words of the transcript.
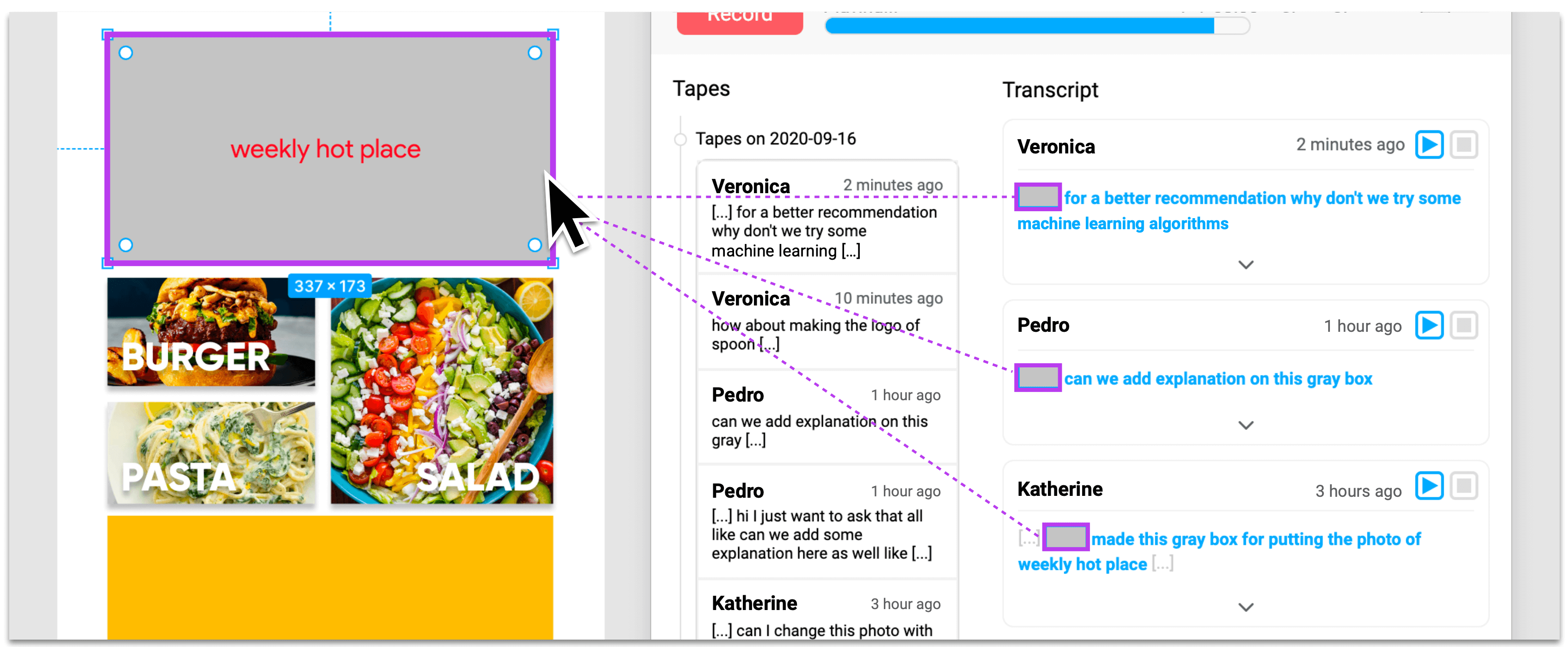
If the user clicks on an object in the UI design, Winder retrieves all tapes in which that object was selected. For each tape, the segment of the tape’s transcript during which the object had been clicked on is shown.
Tapes recorded by participants in a five-day user study were analyzed and categorized. The results showed that participants used Winder for a variety of purposes—with most tapes used for “Describing” or “Justifying” design choices, or “Coordinating” work within a team.
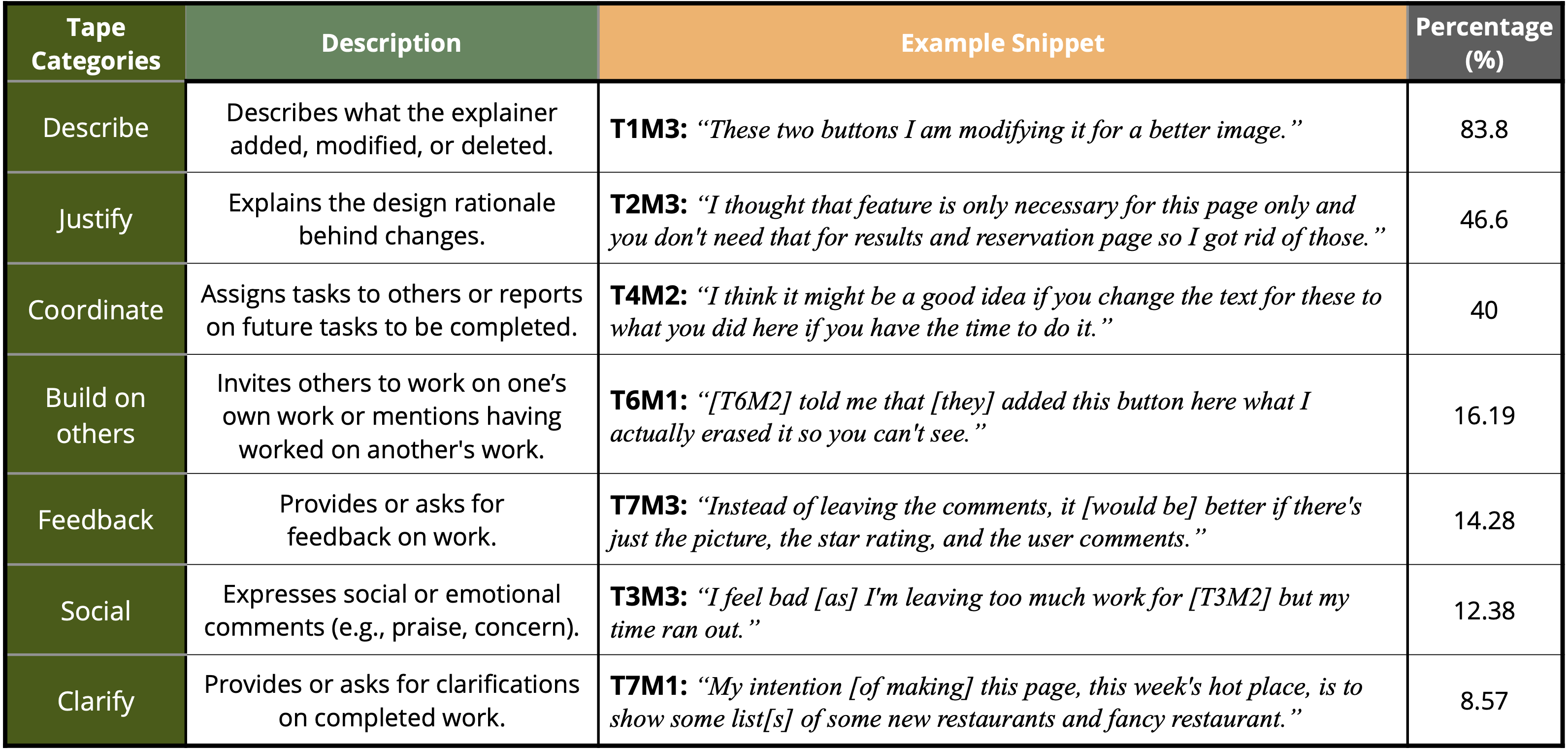
Participants mentioned how Winder increased their shared understanding, motivated them to work, and made them feel as if they were co-present.
T2M1: “The recordings left behind by my group members helped clarify some of the misunderstandings or confusions that I had.”
T1M2: “Understanding [my team members] actions and intentions was fun somehow and made me work harder.”
T5M2: “With the voice recordings and the feature that showed what the users clicked on as they talked, it was as if we were working together.”
@inproceedings{10.1145/3411764.3445686,
author = {Kim, Tae Soo and Kim, Seungsu and Choi, Yoonseo and Kim, Juho},
title = {Winder: Linking Speech and Visual Objects to Support Communication in Asynchronous Collaboration},
year = {2021},
isbn = {9781450380966},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3411764.3445686},
doi = {10.1145/3411764.3445686},
booktitle = {Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems},
articleno = {453},
numpages = {17},
keywords = {Visual Document, Team Collaboration, Speech, User Interface Design., Multimodal Input, Asynchronous Communication, Voice},
location = {Yokohama, Japan},
series = {CHI '21}
}
![]()
![]()
This research was supported by the KAIST UP Program.



